今天来挖个新坑,来用Google出的深度学习框架TensorFlow来搭建一个SoftMax Regression模型,来识别手写数字。
MNIST(Mixed National Institute of Standards and Technology database)是一个机器学习视觉数据集,由像素为28*28的手写数字构成,这些图片只包含灰度值信息,因此每一张图片就是一个28*28*1的矩阵,需要做的就是对这些手写数字图片进行分类,转成0~9共10类。
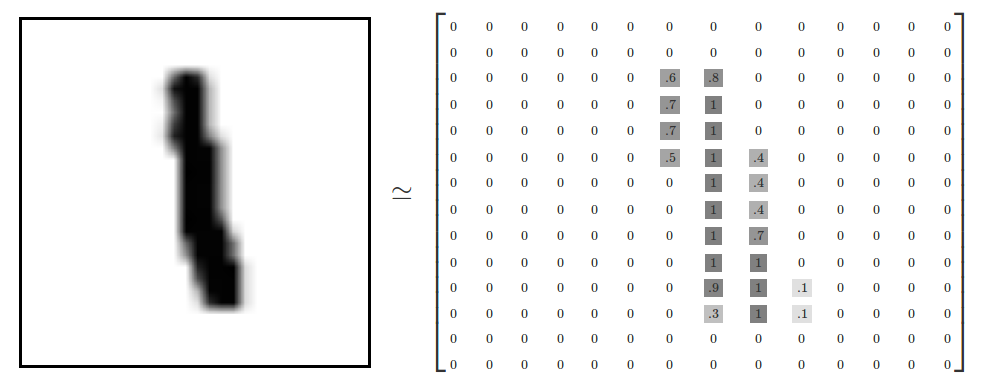
首先需要做的就是对MNIST数据进行加载,TensorFlow已经为我们封装这些功能,直接调用就可实现数据的加载。
|
|
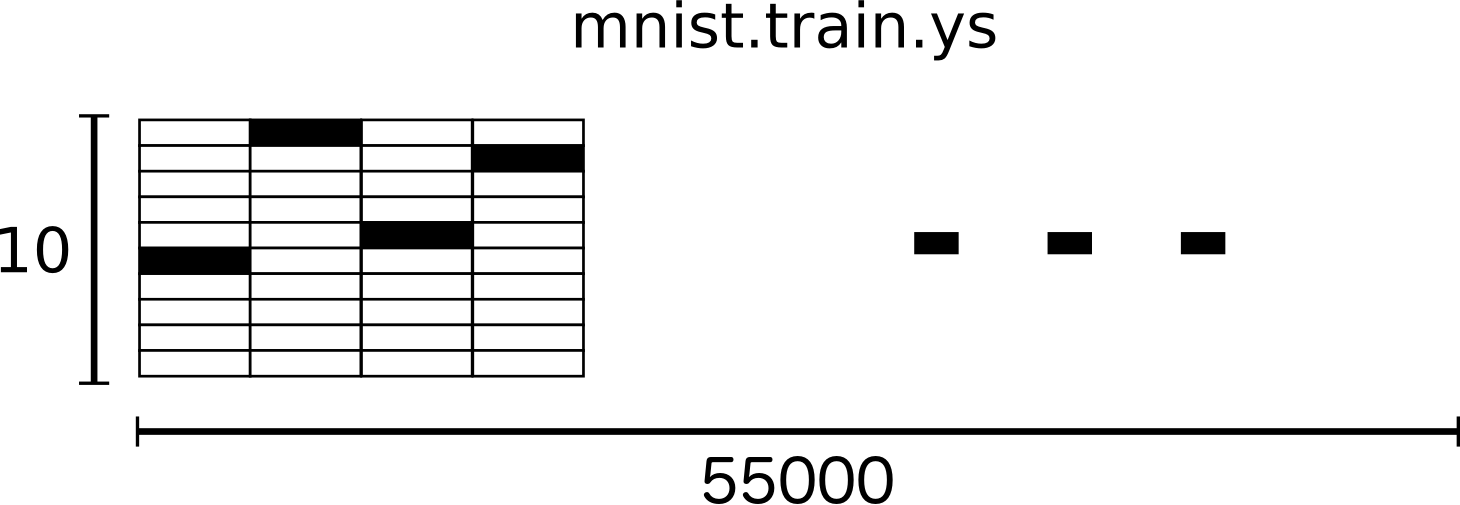
MNIST包含训练集和测试集,每一个样本都有对应的标注信息(label),训练集用来训练设计好的模型,测试集则用来对训练后的模型进行测试。
我们可以通过print()函数打印出MNIST的数据信息
可以看出训练集有55000个样本,测试集有5000个样本,每个样本的维数为784,也就是将每个图像的28*28个点展开成1维的结果(28*28=784),本模型中输入就是这个1维向量,其实这样会失去空间结构的信息,也算是对模型的简化。
因此,模型的输入为55000x784的Tensor,同时Labels为55000x10的tensor。
Softmax Regression的工作原理比较简单,将可以判断为某一类的特征相加,然后将这些特征转化为判定是这一类的概率。上述特征可以通过一些简单的方法得到,比如对所有像素求一个加权和,而权重是模型根据数据西东学习,训练出来的。比如某个像素的灰度值大代表很可能是数字n时,这个像素的权重就大;反之,如果某个像素的灰度大代表不太可能是数字n时,这个像素的权重就比较小,甚至可能是负值。下图为一些这样的特征,其中,明亮的区域代表负的权重,灰暗的区域代表正的权重。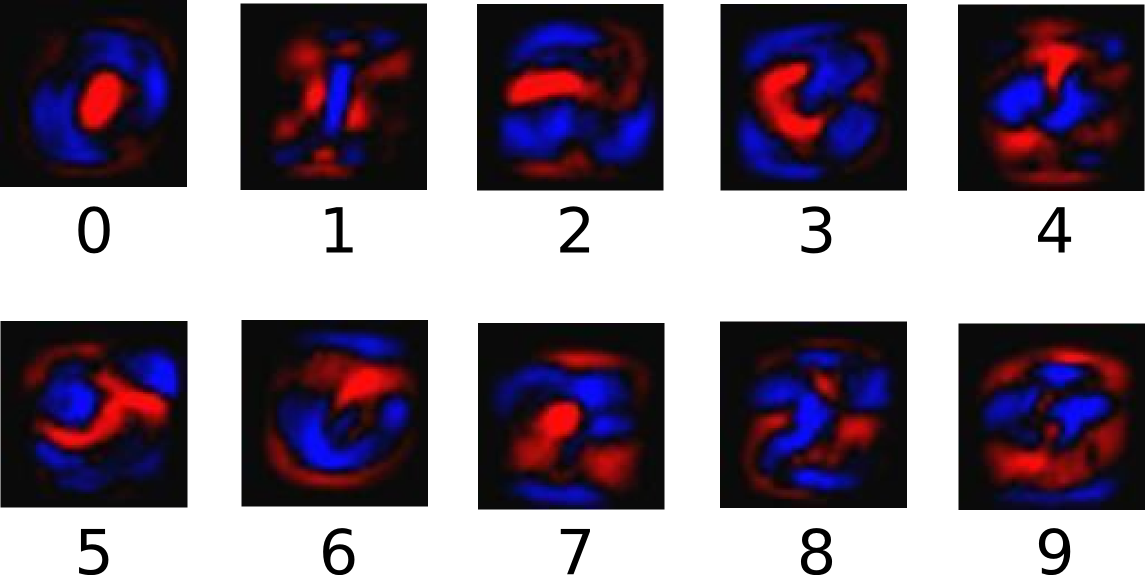
接下来我们将这些特征公式化$i$代表第$i$类,$j$代表一张图片的第$j$个像素。
$$feature_i = \sum_1^n W_{i,j} x_j + b_i$$
接下来对所有特征计算softmax
$$ softmax(x) = normalize(exp(x)) $$
其中第i类的的概率就可以有下面的公式得到:
$$ softmax(x)_i = {exp(x_i) \over \sum_j exp(x_j)} $$
先对各类特征求$\exp$函数,然后对他们标准化,使得和为1,特征是越大的类,最后输出的概率也越大;反之,特征的值越小,输出的概率也就越小.
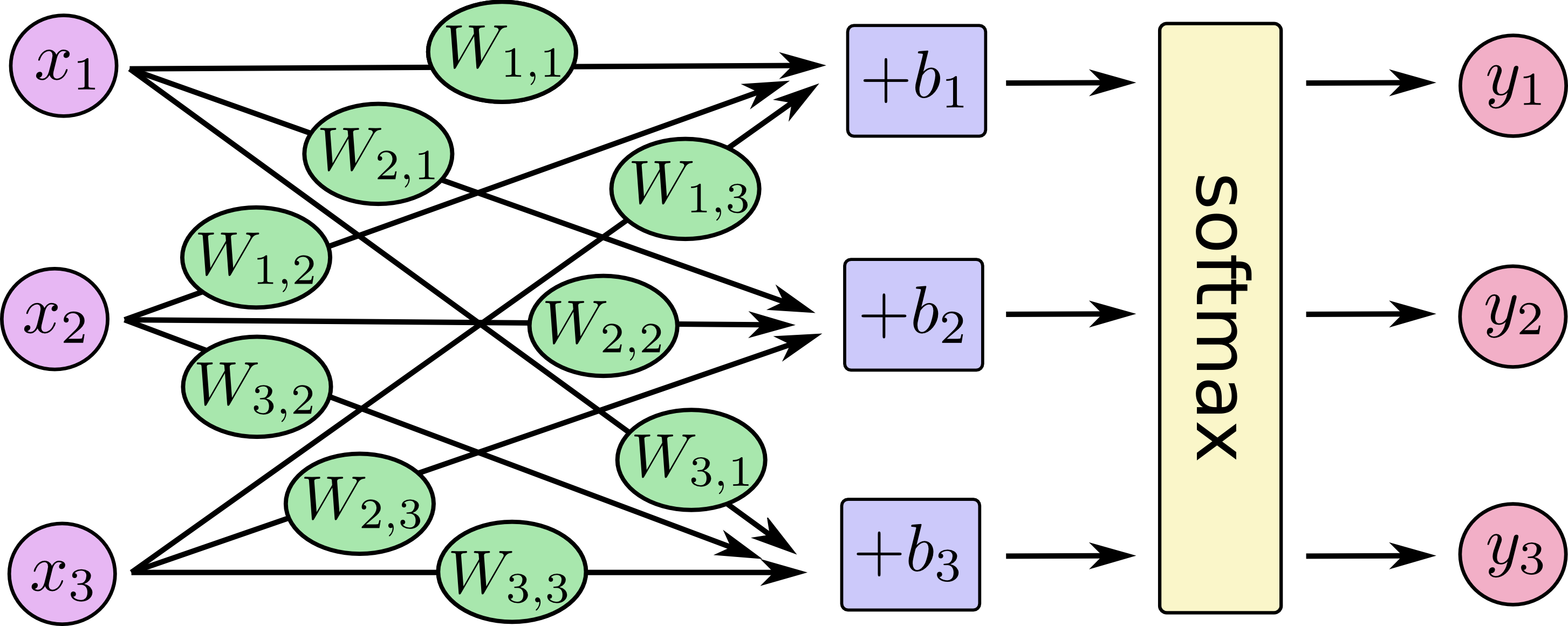
然后就是通过TensorFlow来实现Softmax Regression模型。
首先导入TensorFlow库
然后设置输入和输出,并初始化Weights和Bias
接下来实现Softmax Regression 算法
恩,一行就搞定!
然后用cross-entropy作为loss function.
接下来再定义一个优化方式,直接调用tf.train.GradientDescentOptimizer,并将学习速率设置为0.5,优化目标设置为cross-entropy
下一步就是初始化并执行模型
|
|
加下来就是进行迭代来训练并优化模型。设置迭代次数为1000次,并且每迭代100次用测试数据来测试一下模型的识别正确率,并打印出来

最后在打印出的结果中可以看到,最后Softmax Regression的准确率为92%左右。
参考资料:
- MNIST For ML Beginners
- 《TensorFlow 实战》

